


January 22, 2020
Top Four Features in Confluent Platform 5.4

Apache Kafka sits at the heart of the Confluent Platform, but the platform is much more than just Kafka. And with today’s launch of Confluent Platform version 5.4. the system gets more features demanded by enterprises, including improved clustering, queryable audit logs, and role-based access control, as well as a preview of ksqlDB.
As the enterprise open source company behind Apache Kafka, Confluent has a dual mandate to fulfill. On the one hand, it’s obligated to continue to develop the world’s most popular open source streaming data platform. That means assigning engineers to not only maintain Apache Kafka, but to build new features for the Kafka community, such as its new streaming database, ksqlDB.
But the company’s second mandate is to build a Kafka-based platform that enterprises can rely on to achieve their streaming data plans. That means paying closer attention to the implementation of Kafka in a production environment, and nailing the details around things like security, management, and monitoring.
Those three elements play heavily in today’s release of version 5.4 of Confluent Platform, the enterprise-class Kafka distribution that Confluent sells to corporations and other organizations that want to build streaming data systems that let them harness billions of events in real time.
To that end, here are the top four features added with Confluent Platform version 5.4 (with two bonus features in preview mode):
1. Multi-Region Clusters
The addition of multi-region clustering enables a Confluent customer to stretch a single Confluent Platform (i.e. Kafka) cluster across multiple regions, which bolsters the disaster recovery (DR) capability of customers deploying the product.
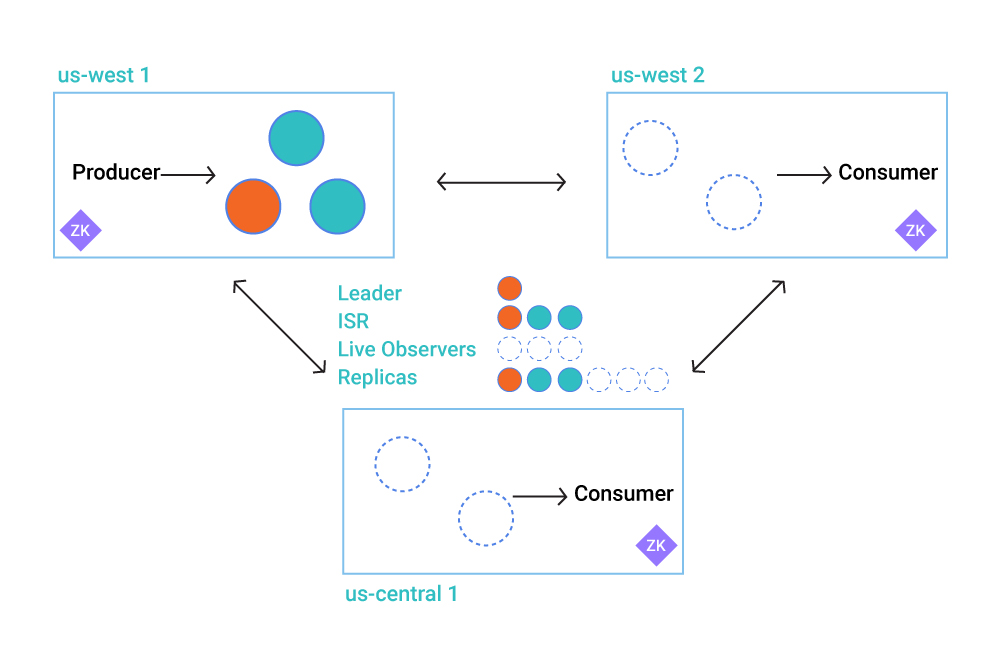
Multi-region clusters bolsters DR (image courtesy Confluent)
Confluent customers have been creating multi-region clusters by essentially “stitching” together two separate clusters using data replication tools, such as Kafka Connect, says Confluent Group Manager Addison Huddy. But this approach was difficult and brought limitations.
“The main limitation to these types of deployments was the ability to do synchronous or asynchronous on a per-topic basis,” Huddy tells Datanami. “So if you were to take a normal Kafka cluster and stretch it, your throughput would be abysmal. The latency between data center would be too high. But if you can do asynchronous synchronization between data centers, you can have a better trade off between durability and availability on a per-topic basis. And that’s only possible in Confluent Platform.”
This feature will be particularly useful for companies that demand the most stringent recovery point objectives (RPOs), such as banks, which typically cannot tolerate any lost data. Confluent counts nine of the world’s top 10 banks as customers, and they depend on Confluent Platform to deliver streaming event data, even through data center outages. “For some banks, Kafka is in the critical path for a credit card authorization,” Huddy says.
2. Structured Audit Logs
For the first time, Confluent is exposing a full audit trail of all user actions to take place on the Confluent Platform cluster, in a format that is readily queryable.
The CloudEvent audit trail format has been embraced by Microsoft Azure (image courtesy Microsoft)
The new audit trails will generate data in the emerging CloudEvent format, and will be readable by tools like Elasticserach and Splunk. This will augment Kafka’s existing logging function, which is not very user-friendly.
Customers will use structured audit logs to bolster visibility of user activity on the Confluent Platform for purposes of security and regulatory compliance, says Praveen Rangnath, senior director of product marketing for Confluent.
“This is something they’re telling us will help them accelerate their deployment of Kafka as a standard,” Rangnath says. “Our customers, in the case of a security event, need to conduct forensics on what happened. They also need an audit trail to adhere to their audit requirement.”
3. Role-Based Access Control
As Kafka use spreads, it’s logical to expect more people to get access to Kafka, and also for the streaming data management system to be used for more sensitive use cases. Both of those trends back the need for more granular control of user access, which is what RBAC delivers.

RBAC provides fine-grained access control (Den Rise/Shutterstock)
Instead of requiring operators to manage access control lists (ACLs) for each Kafka user for each Kafka function, RBAC gives operators the capability to set policies at a higher level, Huddy says.
“Typically you have a situation where you have hundreds of developers and a small team of operators,” Huddy says. “And if you want operators in Confluent at platform scale, that meant managing thousands of ACLs. That became an untenable problem.”
RBAC leverages existing Active Director and Lighweight Directory Access Protocol (LDAP) implementations to grant or deny user acess to Kafka resources. “So rather than deal with fine grain ACLs, you now have a higher-level data abstraction as an operator to lean on LDAP and AD team to define those in the system.”
4. Schema Validation
Just like its database cousins, Kafka uses schemas to organize data and to ensure that it remains usable in the future. Customers define their schemas in the Kafka Schema Registry, which allows users to evolve schemas over time.
With Confluent Platform 5.4, customers can now optionally choose to enforce schemas within the platform, right at the Kafka broker, which on the Confluent Platform is housed in the Confluent Server.
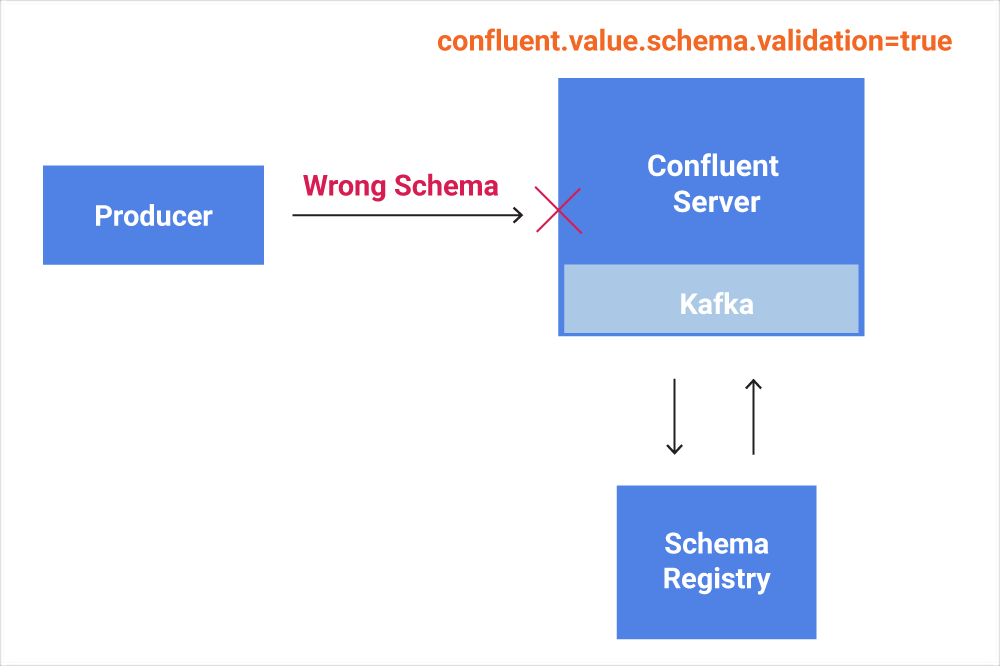
Kafka schemas are validated on the broker in Confluent Platform 5.4 (image courtesy Confluent)
“This is an enterprise feature that lets our customers avoid inconsistencies in the data in their Kafka deployment,” Rangnath says. “What it does is ensure that all the way down to the topic level that all the data they have in Kafka adheres to the proper schema.”
Customers are using Kafka to stream billions of events per day to an array of transactional and analytical systems, so enforcing the structure of the data is critical, Rangnath says. “Having data be cleaned and adhere to a schema is really what unlocks developers to effectively utilize the data.”
Along with these four features, Confluent is offering a preview of two others, including tiered storage and ksqlDB.
With tiered storage, Confluent customers will be able to offload older data to an S3 bucket, freeing the Kafka cluster up to continue processing data. Tiered storage will be a boon to customers that are aggressively adopting Kafka, Rangnath says.
“This is really important for customers who want to maintain a full history of data in Kafka, particularly as they’re utilizing event streaming as the central nervous system of their businesses,” he says.
Lastly, you can start to play around with ksqlDB with Confluent Platform 5.4, although a fully supported version of the feature will have to wait for a future release.
ksqlDB, which debuted in November, is the latest iteration of the streaming SQL query function in Kafka, dubbed KSQL. With ksqlDB, Confluent is morphing the SQL function into a full-blown relational database that is better able to maintain state and to power queries based on that state, which has long been Kafka’s kryptonite.
Related Items:
Confluent Reveals ksqlDB, a Streaming Database Built on Kafka
When – and When Not – to Use Open Source Apache Cassandra, Kafka, Spark and Elasticsearch
Leading Solution Providers

















