


October 29, 2020
Kx Systems: A Historical Need for Speed

(SP-Photo/Shutterstock)
There are a few things that Kx Systems is not. It’s not a new company, for starters, and it’s not a big supporter of open source technology. But if there’s one thing that defines Kx Systems and its approach to helping its clients develop advanced analytics and machine learning systems to work on big data, it’s a relentless focus on speed.
Speed is the defining mantra, the raison d’etre, for Kx Systems and how it seeks to differentiate itself from other providers of advanced analytics software. Speed is why both Wall Street investment banks and Formula 1 racing teams in Europe use the company’s platform, which combines a database, a programming language, and a collection of add-ons for machine learning, real time analytics, and other interesting things that can be done with data.
The speedy roots of Kx Systems go all the way back to the 1960s, when a young Arthur Whitney got his first exposure to programming. Whitney’s father was a friend of Kenneth Iverson, the creator of APL (A Programming Language), an array-oriented programming language. Iverson developed APL at IBM based on research he did into mathematical models for manipulating arrays while at Harvard.
An 11-year-old Whitney was lucky enough to get a demo of interactive programing with APL directly from Iverson back in 1969, according to an April 2009 interview with Whitney published by the Association of Computing Machinery. In the 1980s, Whitney would go on to work with APL and with Iverson, who received the Turing Award for his work on APL. But Whitney decided his real passion was pure mathematics, so he joined the University of Toronto and enrolled in its graduate math program.

Kx Systems co-founder Arthur Whitney was heavily influenced by Kenneth Iverson’s APL
It wasn’t until Whitney left school and joined Morgan Stanley in 1988 that he would begin working with APL again, and eventually set him on a course to developing three new languages based on APL, including A+, k, and eventually q.
Morgan Stanley had one of the biggest trading operations on the planet, and a 1TB database of trading data, which was a big data set for the day, according to the ACM interview. Whitney tried using other languages, but eventually settled on APL to write a program that could analyze that “tick” data to find trading opportunities for Morgan Stanley and its billion-dollar portfolio.
At Morgan Stanley, Whitney would go on to develop several other languages based on APL, including A+, which was used to migrate APL applications from IBM mainframes to Sun workstations. He also created a language called k, which, like A+, was rather spartan in its brevity, and designed to deliver lightning-fast processing of time-series data.
“My motivation was always to create a general-purpose programming language that would solve all problems and be interpreted, but fast,” Whitney said in the ACM interview.
A Speedy Beginning
In 1993, Whitney left Morgan Stanley to co-found Kx Systems with the goal to commercialize the language k. The company signed an exclusive contract with the Swiss bank UBS to develop trading systems based on k, and a year after that contract ended, in 1998, Kx Systems released kdb+, a proprietary database built on k.
In 2003, Kx Systems would release q, a follow-on to the k language that was designed to work with the kdb+ database. While k was renown for its sparseness, q was more verbose, hence it was more readable, but just as fast.
The company’s primary customers continued to be Wall Street banks that needed to analyze large amounts of data very quickly. As the volumes of trades and available data grew, the banks turned to companies like Kx Systems to help them develop algorithmic trading strategies.
Kx Systems’ software was originally used to implement algorithmic trading strategies at Wall Street investment banks (Pixels Hunter/Shutterstock)
Kx Systems was helping its clients solve “big data” problems 20 years before “big data” became a thing, says Dan Seal, chief product officer for Kx Systems.
“When I first saw big data come to the market, I was really confused because I was seeing these guys talk about datasets that to me didn’t seem that big, and they seemed limited in their capability,” Seal tells Datanami in a recent interview.
Back in the year 2000, when Seal was still in university, Kx Systems was selling distributed systems that could process streaming data in real-time, while maintaining a historical record of data.
That is something that companies still struggle with today, says Seal. And the reason they’re struggling with it is because they’re having to cobble together multiple systems to get that capability. Kx Systems, meanwhile, delivers it all in one integrated stack – a proprietary stack, of course, but a functional one, he says.
Efficiency and Scale
Kx Systems software is still used by trading firms, but the scale is much, much greater than what Whitney worked on during those early days at Morgan Stanley. Today, traders are must cope with millions of events per second, with decision windows for trading engines measured in the microseconds. Trading models are implemented on GPUs and FPGAs to maximize performance.
While the big data battle continues on Wall Street, other industries have sought out Kx Systems to help them develop highly tailored applications to work with large amounts of incoming data and large historical datasets too. Today, Kx Systems is helping clients across a range of industries work on time-series data. That includes log capture, network analytics, cyber security, space, and IoT, including connected cars.

The Aston Martin Red Bull racing team uses Kx Systems software to analyze 18 billion rows of data generated by 600 sensors on each car for each race
The common thread across the implementations in different industries is the nature of the data itself, Seal says.
“That’s been one of the interesting things to see. It went from being ‘time-series is a niche thing in financial markets’ to people suddenly realizing, actually the whole world is oriented on time,” he says. “Time-series is the digitalization of our entire world. Whether it’s clickstream from a website or log stores from Splunk, everything is time-based analytics.”
Lots of vendors are trying to tackle this problem, from the data warehousing and NoSQL database vendors to the streaming analytics platforms and in-memory data grids. But they tend to tackle the problem either from the historical or the real-time points of view. Kx Systems, meanwhile, sits the middle, with a view of both from a platform built around a speedy database that features its own speedy language.
“Analytics and aggregation is really at the heart of what kdb+ and Kx is, particularly around time-oriented operations,” Seal says. “When Arthur Whitney was building a programming language, this was at the heart of what he was trying to do: build a fast aggregation and analytics language for data science and analysis.”
For example, if you wanted to see what the market quote for a particular stock was at the moment a trade occurred, that requires doing a time-oriented join of two data sets, which might have tens or hundreds of millions of rows each.
“If you try and do something in the traditional SQL database where you line those two data sets up so you can see what the prevailing quote was a the time of the trade, you would see an awful lot of code,” Seal says. “That’s a single functional operator in kdb,” he says. (It’s actually call an “asof join,” because it tells you the state of something “as-of” a particular point in time.)
IoT may be the next big opportunity for Kx Systems. Self-driving cars and connected cars, for example, will need data platforms that can make fast decisions on incoming data, while keeping an eye on the longtail of data for training machine learning models. Many vendors are developing new products or positioning old ones to handle the opportunities emerging on the edge.
Fast and Small
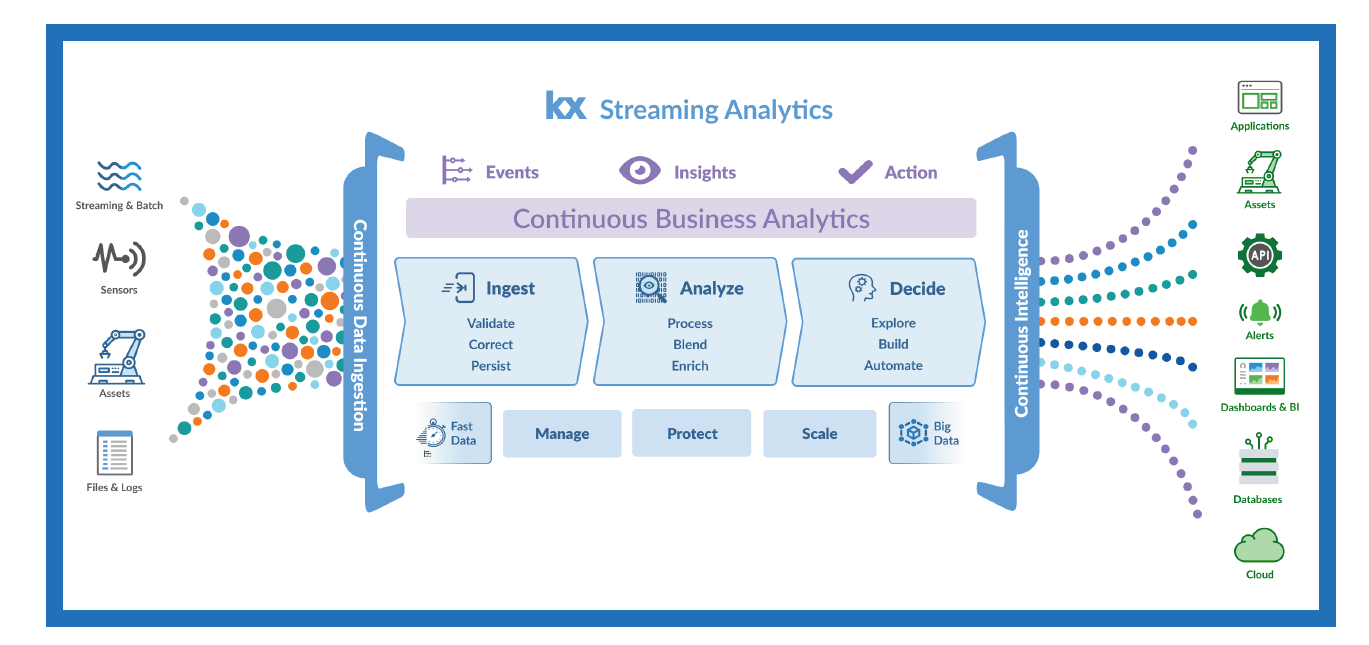
Kx Systems real-time analysis system is a soup-to-nuts stack that’s proprietary (but you can still use your Python models)
Seal marveled at Microsoft’s boasting that its new version of SQL Server for the edge weighed in at a scant 500MB. “We’re 500KB, half a megabyte, for the core database and programming language,” he says. “That’s it.”
That doesn’t get you the full Kx Systems analytics stack, Seal reminds us. But it’s all the space you need to get the core capability to connect to sensors, collect data, and perform some analytics on the spot, while the heavy lifting is done in the full environment running in the cloud or in a customer’s data center.
That, in a nutshell, is Kx Systems’ primary value. In order to get that high performance, you need to take speed into account from the very beginning, and design everything around that principle. If you just solve one piece of the puzzle, you’re not addressing the whole problem, Seal says.
“A primary output of data science and quantitative research is new analytics and machine-learning models to fulfill application use cases for the business,” he says. “Our integrated streaming analytics platform covers not only multi-petabyte historical datasets and sandboxes for data science but is fast enough, scalable enough and dependable enough to be used directly by developers inline, as an integrated part of of their application. Unless you can cover that full spectrum of workloads, you’re only solving part of the problem and not solving for total analytics.”
Related Items:
Streaming Analytics: The Silver Bullet for Predictive Business Decisions
The Real-Time Future of Data According to Jay Kreps
Go Fast and Win: The Big Data Analytics of F1 Racing
Applications:
Data Mining
Tags:
A+, APL, Arthur Whitney, big data, Dan Seal, k, kdb+, Kx Systems, machine learning, q, real-time streaming
Leading Solution Providers

















