


April 6, 2022
Google Cloud Opens Door to the Lakehouse with BigLake

(Francesco Scatena/Shutterstock)
Google Cloud made its way into the lakehouse arena today with the launch of Big Lake, a new storage engine that melds the governance of its data warehousing offering, BigQuery, with the flexibility of open data formats and the ability to use open compute engines. The company also used the opening of its Data Cloud Summit to announce a preview of BigBI, which extends Looker’s semantic data layer to other BI products.
Google Cloud is no stranger to data lakes, with its Google Cloud Storage offering, which offered nearly limitless storage for less-structured data in an object storage system that is S3 compatible. It also is a leader in data warehousing via BigQuery, which provides traditional SQL processing for structured data.
While Google Cloud has made progress in improving the scale and flexibility of both storage repositories, customers often gravitate to one storage environment or the other depending on the type of data they’re working with, according to Sudhir Hasbe, senior director of product management Google Cloud.
“You start with structured data. ‘This is your orders and shipments in a retail environment,’” Hasbe said during a press conference on Monday. “Then semi-structured data with clickstream comes in, and then over a period of time you have unstructured data around product images and machine as well as IoT data that we’re getting collected.
“And so all of these different types of data are being stored across different systems, whether it’s in data warehouses for structured data or semi-structured, or its data lakes for…all the other types of data. And these provide different capabilities historically, and that actually creates lot of data silos.”
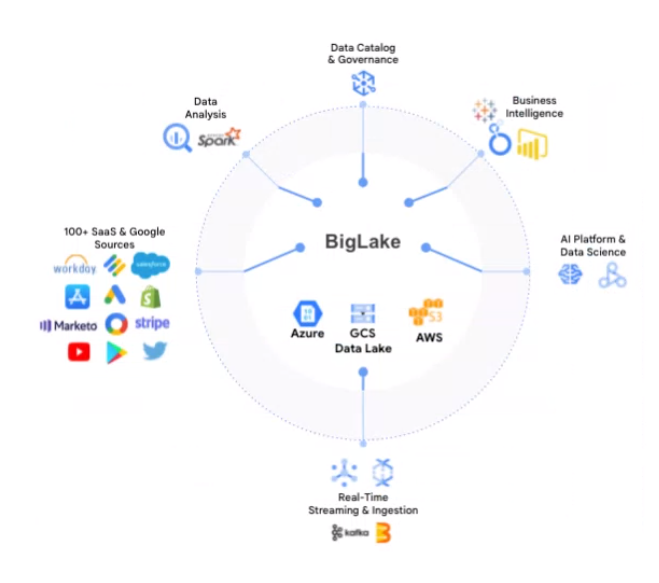
Google is melding its data warehouse with its data lake with BigLake (Image courtesy Google Cloud)
These data silos–and the problems that are associated with data silos–begin to dissipate with BigLake, Hasbe said.
“Specifically, BigLake allows companies to unify the data warehouse and lakes to analyze data without worrying about the underlying storage format or systems,” Hasbe said. “The biggest advantages then you don’t have to duplicate your data across two different environments and create data silos.”
What Google Cloud has done with BigLake is it has taken the governance, security, and performance-management capabilities that it has already developed in BigQuery and it has extended it into Google Cloud Storage, the company’s data lake environment. According to Hasbe, these capabilities have also been extended to data lakes offered by AWS and Microsoft Azure too.
Two other important components of BigLake is support for open standards and support for open processing engines, which are components of BigLake’s support for Dataplex, Google Cloud’s data fabric solution, Hasbe said.
Big Lake customers will be able to store their data in popular open data formats, such as Parquet and ORC, in addition to emerging formats, such as Iceberg. BigLake will enable customers to bring the data governance and performance management capabilities of BigQuery to bear against the large data sets they have stored in these formats, the Google product manager said.
“So this way, you break down the silos, you get the innovation that Google has invested in for more than decade, and you still keep your open formats and open standards that you love as an organization,” Hasbe said. “BigLake is the center of our strategy. It’s basically we’re going to make sure all the tools and capabilities we have built overtime seamlessly integrate with big lake.”
On the processing engine front, customers will be able to bring all of Google’s compute engines to bear on data stored in BigLake, Hasbe said. That includes the BigQuery engine, in addition to Spark, DataFlow, DataProc, and others.
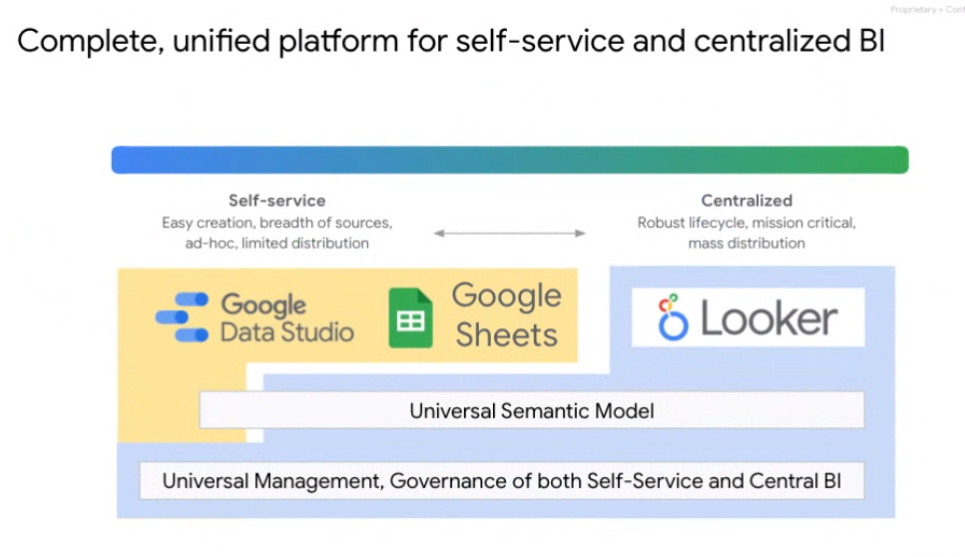
BigBI will provide a common semantic layer for consistent metrics across BI products (Image courtesy Google Cloud)
Google Cloud isn’t the first vendor to offer a lakehouse product to customers, and interestingly, BigLake isn’t the first time Google Cloud has embraced the concept. But Databricks is credited with spearheading the category several years ago with the launch of its Delta Lake offering. AWS has also embraced the architectural concept. Many other companies in the open data ecosystem, from Dremio to Starburst, are lakehouse backers. What about Snowflake, the Cloud data warehousing giant? Not so much.
“It is time that we end the artificial separation between managed warehouses and data lakes,” said Gerrit Kazmaier, Google’s vice president and general manager for database, data analytics and Looker. “Our innovation at Google Cloud is that we take BigQuery and its unique architecture as a unique serviceless model, a unique storage architecture, a unique compute architecture, and we extend this now to open source file formats and open source processing engines.”
Google is also rolling out a preview of BigBI, Google’s new offering for unified self-service analytics. The key innovation in BigBI is the extension of Looker’s semantic modeling layer into other BI tools in Google Cloud’s stack, including Data Studio, Looker, and Google Sheets. This semantic layer will provide much needed consistency to the metrics that various stakeholders develop when working in a self-service environment.
The lack of standardization of metrics is a big hurdle in self-service BI, Hasbe said. “For example, I may define a dashboard. It has a metric called gross margin,” he said. “I may include marketing expenses in it. My colleague, who is in the merchandising department, they define gross margin as a metric that includes merchandising costs but not marketing.”
This lack of standardization leads to errors, which is bad for everybody. BigBI addresses this problem by getting everybody on the same page when it comes to metrics.
“Looker actually solves this exact problem by centralizing the common understanding of metrics in an organization,” Hasbe continued. “We call it centralized or governed BI. And so today we are bringing these two worlds together. Now you can use the self self service power of tools like Data Studio or Tableau and use the central model of looker semantic layer, where you can define your metrics in a one single place and all the self service tools will seamlessly work and engage with them.”
Google Cloud’s Data Cloud Summit is a one-day event taking place today.
Related Items:
Lakehouses Prevent Data Swamps, Bill Inmon Says
Leading Solution Providers

















