


August 22, 2022
A Data Platform for Chatbot Development

(sdecoret/Shutterstock)
One of the most compelling use cases for AI at the moment is developing chatbots and conversational agents. While the AI part of the equation works reasonably well, getting the training data organized to build and train accurate chatbots has emerged as the bottleneck for wider adoption. That’s what drove the folks at Dashbot to develop a data platform specifically for chatbot creation and optimization.
Recent advances in natural language processing (NLP) and transfer learning have helped to lower the technical bar to building chatbots and conversational agents. Instead of creating a whole NLP system from scratch, users can borrow a pre-trained deep learning model and customize just a few layers. When you combine this democratization of NLP tech with the workplace disruptions of COVID, we have a situation where chatbots appear to have sprung up everywhere almost overnight.
Andrew Hong also saw this sudden surge in chatbot creation and usage while working at a venture capital firm a few years ago. With the chatbot market expanding at a 24% CAGR (according to one forecast), it’s a potentially lucrative place for a technology investor, and Hong wanted to be in on it.
“I was looking to invest in this space. Everybody was investing in chatbots,” Hong told Datanami recently. “But then it kind of occurred to me there’s actually a data problem here. That’s when I poked deeper and saw this problem.”
The problem (as you may have guessed) is that conversational data is a mess. According to Hong, organizations are devoting extensive data science and data engineering resources to prepare large amounts of raw chat transcripts and other conversational data so it can be used to train chatbots and agents.
The problem boils down to this: Without a lot of manual work to prep, organize, and analyze massive amounts of text data used for training, the chatbots and agents don’t work very well. Keeping the bots running efficiently also requires ongoing optimization, which Hong’s company, Dashbot, helps to automate.
‘Undecipherable Hieroglyphics’
Computers can understand 0s and 1s. Human conversation? Not so much.
“A lot of this is literally hieroglyphics,” Hong said of call transcripts, emails, and other text that’s used to train chatbots. “Raw conversational data is undecipherable. It’s like a giant file with billions of lines of just words. You really can’t even ask it a question.”
While a good chatbot seems to work effortlessly, there’s a lot of work going on behind the scenes to get there. For starters, raw text files that serve as the training data must be cleansed, prepped, and labeled. Sentences must be strung together, and questions and answers in a conversation grouped. As part of this process, the data is typically extracted from a data lake and loaded into a repository where it can be queried and analyzed, such as a relational database.

(Jason Winter/Shutterstock)
Next, there’s data science work involved. On the first pass, a machine learning algorithm might help to identify clusters in the text files. That might be followed by topic modeling to narrow down the topics that people are discussing. Sentiment analysis may be performed to help identify the topics that are associated with the highest frustration of users.
Finally, the training data is segmented by intents. Once an intent is associated with a particular piece of training data, then it can be used by an NLP system to train a chatbot to answer a particular question. A chatbot may be programmed to recognize and respond to 100 or more individual intents, and its performance on each of these varies with the quality of the training data.
Dashbot was founded in 2016 to automate as many of these steps as possible, and to help make the data preparation as turnkey as possible before handing the training data over to NLP chatbot vendors like Amazon Lex, IBM Watson, and Google Cloud Dialogflow.
“I think a tool like this needs to exists beyond chatbots,” said Hong, who joined Dashbot as its CEO in 2020. “How do you turn unstructured data into something usable? I think this ETL pipeline we built is going to help do that.”
Chatbot Data Prep
Instead of requiring data engineers and data scientists to spend days working with huge number of text files, Hong developed Dashbot’s offering, dubbed Conversational Data Cloud, to automate many of the steps required to turn raw text into the refined JSON document that the major NLP vendors expect.
“A lot of enterprises have call center transcripts just piling up in their Amazon data lakes. We can tap into that, transform that in a few seconds,” Hong said. “We can integrate with any conversational channel. It can be your call centers, chat bots, voice agents. You can even upload raw conversational files sitting on a data lake.”
The Dashbot product is broken up into three parts, including a data playground used for ETL and data cleansing; a reporting module, where the user can run analytics on the data; and an optimization layer.
The data prep occurs in the data playground, Hong said, while the analytics layer is useful for asking questions of the data that can help illuminate problems, such as: “In the last seven days how many people have called in and asked about this new product line that we just launched and how many people are frustrated by it?”
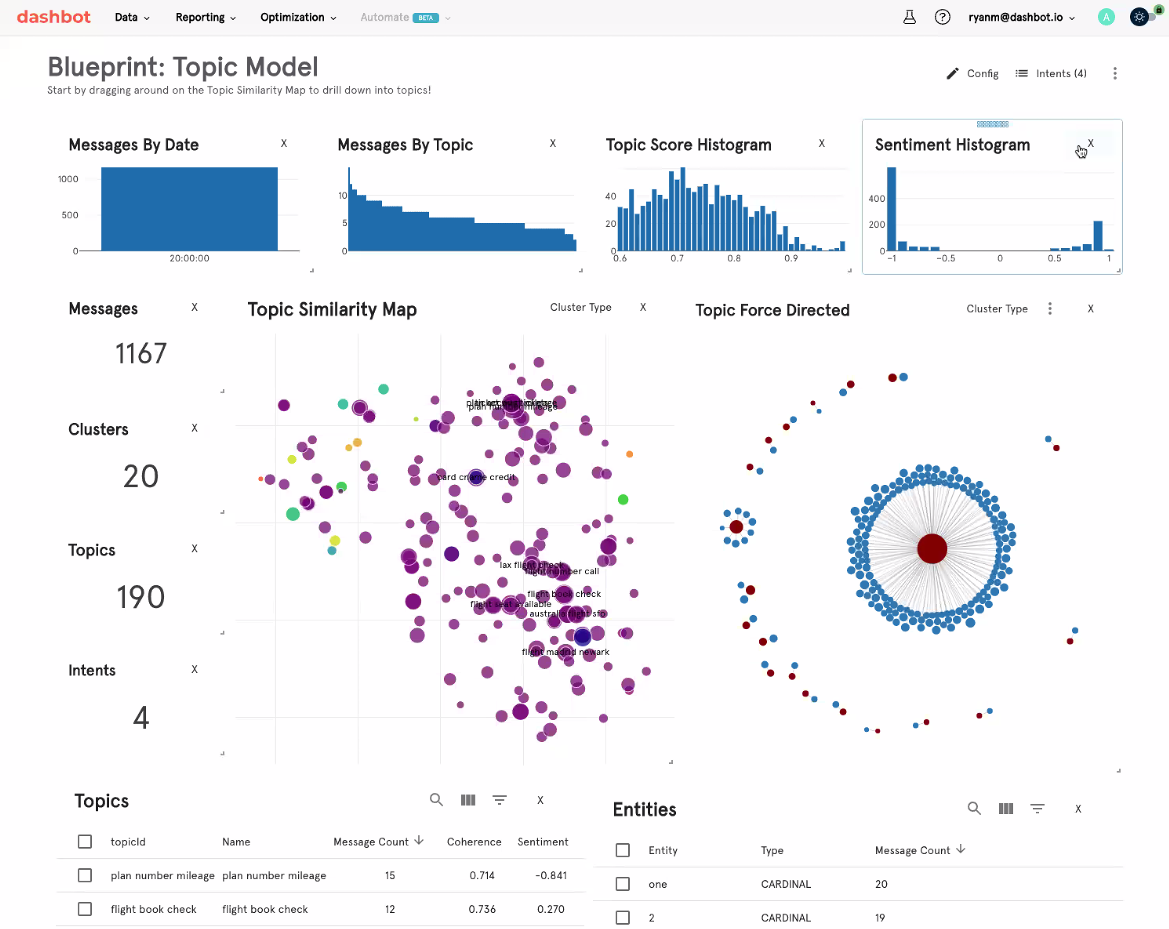
Dashbot helps conversational designers optimize training data for chatbots (Image courtesy Dashbot)
The optimization layer can help a user identify instances where the chatbot is being erroneously trained. To train a chatbot, the NLP system must have the correct training phrase associated with a given intent. Dashbot features a confusion matrix that can identifying when there’s a mismatch between the registered intent and underlying training data.
“Building these intents and training phrases is the hardest part,” Hong said. “This is where a lot of enterprises struggle. You have to default to hiring a lot of data scientists to try to figure this out.”
For example, for the input phrase “Hey, I want to book a driver’s license test this Saturday,” the chatbot might respond “OK you want to cancel your appointment,” Hong said. “That training phrase is in the wrong intent, and your bot responded incorrectly. So you need to start to disambiguate.”
In addition to identifying mismatches between intents and training phrases, the Dashbot product can also show the conversational designer areas where new intents are needed, each with its requisite (and appropriate) training phrases.
“We’re kind of this integration layer that sits across the ecosystem,” Hong said. “Some of these bot vendors are also these NLP model vendors as well. They just essentially collect these intents and training phrases. They have this library that is your model. They don’t actually help you in optimizing the model. It’s up to you and data scientists and teams of managers to help improve it yourself. So we are tooling to help optimize that and feed it into these providers.”
The San Francisco company has raised $8.2 million in venture funding and has attracted customers like Geico, Intuit, and Google, according to its website.
Related Items:
Natural Language Processing: The Next Frontier in AI for the Enterprise
Google’s ‘Breakthrough’ LaMDA Promises to Elevate the Common Chatbot
Applications:
Artificial Intelligence
Technologies:
Cloud
Sectors:
Retail
Vendors:
Dashbot
Tags:
Andrew Hong, chatbot, conversational agent, data pipeline, data preparation, ETL, intents, NLP
Leading Solution Providers

















