


November 29, 2022
AWS Unleashes the DataZone

(phM2019/Shutterstock)
Managing data at scale is arguably the biggest impediment companies face when it comes to getting value out of their data. With that in mind, AWS today announced Amazon DataZone, a new data management service designed to help customers catalog, discover, share, and govern data, no matter where it resides.
While analytics and machine learning can move the needle for companies, too often companies struggle to manage and govern the data at scale. This has been a recurring theme in 2022, as big data vendors respond to companies’ struggles to put advanced analytics and AI into production.
Today it was cloud giant AWS’ turn at the big data till, and AWS CEO Adam Selipsky was driving. The destination: DataZone. He started by framing the problem.
“Finding the right balance between control and access is crucial but it’s different for every organization,” Selipsky said today during his keynote address at re:Invent, which is taking place in Las Vegas this week. “Too much control and your data gets locked in silos. People can’t find what they need when they need it and it stifles innovation and kills creativity, and they end up going around you, creating shadow IT systems that leave your data out of date, incomplete, and definitely unsecure.”
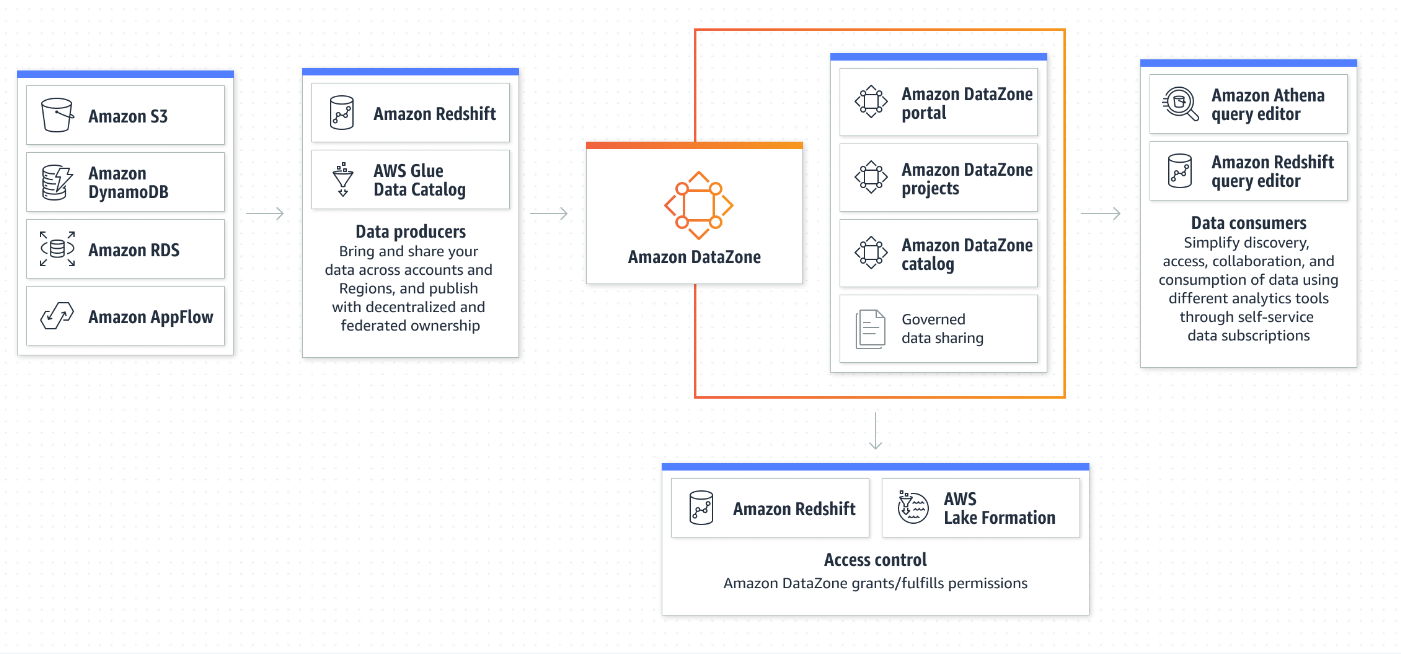
Source: AWS
However, grant too much access to data, and you can have an equally bad impact on your organization, Selipsky said. It can end up in places where you don’t want it to be, putting the privacy and security of your employees and customers at risk.
“Establishing the right governance, one that lets you balance control and access, gives people within the organization trust and confidence,” he said. “But implementing data governance across an organization is complicated. You have all sorts of people with all sorts of different use cases, and all sorts of data spread across multiple departments, services, databases, third party applications, and more.”
DataZone addresses this challenge by enabling administrators and data stewards to manage and govern access to data. The offering, which is currently in preview, should help data engineers, data scientists, data analysts, product managers, and business users access the data they need to get their jobs done. It works with customer data residing in the AWS cloud, on-premise systems, and third-party sources, AWS said.
“DataZone enables you to set data free throughout the organization,” Selipsky said.
The service provides a Web portal where data producers can create DataZone catalogs that define the taxonomy of the data, or its business glossary. Users can create different taxonomies for different business units, according to AWS. Machine learning is used to populate the appropriate metadata into the catalog for each piece of data, and users can add their own labels and descriptions too.
“Now anyone wanting to access the data can search the catalog and discover data assets using familiar terms,” Selipsky said. “They can examine the metadata and requests access to the data by creating a new data project.”
Data projects in DataZone help bring together the people, the data, and the analytics tools, such as Redshift, Athena, or QuickSight. There are also APIs available that let users bring third-party tools, such as Snowflake and Tableau, into the mix.
“Now you have an easy way to organize, discover, and collaborate on data across the company,” Selipsky says. “There’s really nothing else like it, and I’m really excited to see how you’re going to use it.”
For more information on DataZone, check out today’s press announcement, or the DataZone product page.
Related Items:
AWS Introduces a Flurry of New EC2 Instances at re:Invent
What’s Holding Up Progress in Machine Learning and AI? It’s the Data, Stupid
MIT and Databricks Report Finds Data Management Key to Scaling AI
Leading Solution Providers

















