


February 10, 2023
AnyScale Bolsters Ray, the Super-Scalable Framework Used to Train ChatGPT

(Blue Andy/Shutterstock)
ChatGPT developer OpenAI is using Ray, an open-source unified compute framework, to ease the infrastructure costs and complexity of training its large language models. Anyscale, the company behind Ray, has made enhancements and improvements to the platform’s newest version, Ray 2.2, in order to support the current AI explosion.
With all the excitement surrounding ChatGPT and LLMs, it is easy to overlook just how much work goes into bringing these seemingly magical models into existence. There is not just the data science and machine learning work, but also the development work of building and operating the complex computing infrastructure required for training and deploying these models. As shown by the estimated $12 million it cost to train the 175 billion parameter GPT-3 in 2020, the vast amount of time and resources needed to train and deploy LLMs can be staggering.
Robert Nishihara, CEO and co-founder of Anyscale, agrees: “AI is growing, but the amount of compute needed to do AI is off the charts,” he said in an interview with Datanami.
![]() Distributed computing, or multiple computers running multiple software components as a single system, is one way to bring down infrastructure complexity and costs for AI projects. Ray automates many of the development tasks that take attention away from AI and ML work and increases the performance and cost-efficiency of distributed systems. The platform was created by Nishihara and his colleagues at UC Berkeley’s RISELab and is now commercially available for enterprise use through Anyscale.
Distributed computing, or multiple computers running multiple software components as a single system, is one way to bring down infrastructure complexity and costs for AI projects. Ray automates many of the development tasks that take attention away from AI and ML work and increases the performance and cost-efficiency of distributed systems. The platform was created by Nishihara and his colleagues at UC Berkeley’s RISELab and is now commercially available for enterprise use through Anyscale.
OpenAI uses Ray to train its largest models, including those powering ChatGPT. At Anyscale’s Ray Summit last year, OpenAI President and Co-founder Greg Brockman shared how Ray became an integral part of the training of the company’s LLMs. In a fireside chat with Nishihara, Brockman explained that OpenAI was looking for better ways to architect its machine learning systems and went with Ray after exploring several options. “We’re using it to train our largest models. It’s been very helpful for us to scale up to an unprecedented scale,” he said.
Ray distributes the work of training an ML model across the multiple (in OpenAI’s case, thousands) CPUs, GPUs, and other hardware components comprising the training system. Using the programming language Python, the platform manages each hardware component as a single unit, directs data to where it needs to go, and troubleshoots failures and bottlenecks.
![]() Time and resource costs can make or break AI projects, and Nishihara says that platforms like Ray can bring AI success within reach: “The exciting thing about building this platform is you have users doing amazing things. We think AI has the potential to really transform so many different industries, but it’s very hard to do. A lot of AI projects fail. A lot of them become successful prototypes but don’t make it to production,” he said. “The infrastructure and the tooling around AI is one of the big reasons that it’s hard. If we can help these companies move faster to succeed with AI, to get value out of AI, to do the kinds of things that Google or OpenAI does, but not have to become experts in infrastructure … that’s something we are very excited about.”
Time and resource costs can make or break AI projects, and Nishihara says that platforms like Ray can bring AI success within reach: “The exciting thing about building this platform is you have users doing amazing things. We think AI has the potential to really transform so many different industries, but it’s very hard to do. A lot of AI projects fail. A lot of them become successful prototypes but don’t make it to production,” he said. “The infrastructure and the tooling around AI is one of the big reasons that it’s hard. If we can help these companies move faster to succeed with AI, to get value out of AI, to do the kinds of things that Google or OpenAI does, but not have to become experts in infrastructure … that’s something we are very excited about.”
Ray was initially designed as a general-purpose system for running Python applications in a distributed manner and was not specifically made for ML training purposes, but it has become sought after for computationally intensive ML tasks. Besides model training, Ray is also used for model serving, or hosting a model and making it available through APIs, as well as batch processing workloads. Anyscale power users, like OpenAI, can use the “deep” integration of Ray which involves using Ray APIs or libraries to run applications in a serverless manner on the public cloud. Brockman has found Ray to be useful for developer productivity in general: “Large model training is where it really started, but we’ve seen it really spiral out to other applications, like data processing and scheduling across multiple machines, and it’s really convenient to just run that on top of Ray, and not have to think very hard,” he said during his Ray Summit interview.
These are some of the available integrations for the Ray platform. (Source: Anyscale)
One of Ray’s strengths is its ability to integrate with machine learning platforms and other development frameworks, such as TensorFlow and PyTorch. To that end, Anyscale recently announced an integration with Weights & Biases, an MLOps platform specializing in experiment tracking, dataset versioning, and model management, which are parts of the machine learning process that Ray does not specifically address. Nishihara explained that this integration optimizes the user experience for customers of Anyscale and Weights & Biases by increasing monitoring capabilities and reproducibility for machine learning projects.
“When you’re looking at something in the Weights & Biases UI, you can click back to find the experiment logs in Anyscale to see what experiments were run, and you can click a button to reproduce that experiment. From the Anyscale UI, as you’re doing machine learning training, there’s a link to navigate back to Weights & Biases. All of the information is there to seamlessly use the two platforms together,” said Nishihara.
Anyscale also recently released Ray 2.2, which it says offers improved developer experience, performance, and stability. The dimension of performance is a top priority for Nishihara: “Performance can mean a lot of things—scalability, speed, cost efficiency—all of these things are important. Leading up to Ray 2.0, a lot of our focus was on stability and making it rock solid. Now reliability is in a good spot, and a lot of the improvements we are trying to make are around performance,” he said.
Ray 2.2 features improved dashboards, debugging tools, and tools for monitoring memory performance. The update focused on reducing latency and memory footprint for batch prediction for deep learning models by avoiding unnecessary data conversions. The company says Ray 2.2 offers nearly 50% improved throughput performance and 100x reduced GPU memory footprint for batch inference on image-based workloads.
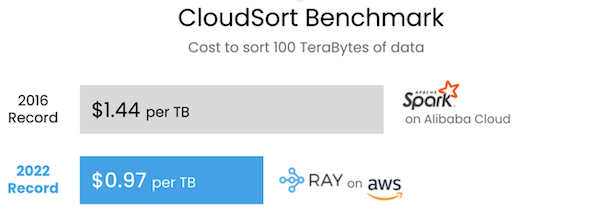
Results of the CloudSort Benchmark. (Source: Anyscale)
Ray recently helped the Sky Computing Lab at UC Berkeley set a world record on the CloudSort benchmark that broke through the $1/TB barrier, demonstrating the platform’s ability to reduce costs and resources. The lab developed Exoshuffle, a new architecture for building distributed shuffle that is built upon Ray. Shuffling is the process of exchanging data between partitions, and in this benchmark, the team was able to sort 100TB of data on the public cloud using only $97 of cloud resources, or $0.97 per terabyte. Anyscale says this is 33% more cost-efficient than the previous world record set by Apache Spark in 2016 at $1.44 per terabyte. Spark is specialized for data processing, unlike general-purpose Ray, but in this case, the specialized system did not outperform the general system, says Nishihara. He also explains how the benchmark also showed how simple it can be to integrate Ray: “Because Ray handles all of the distributed computing logic for you, the team was able to implement all the sorting logic and algorithms as an application on top of Ray. They didn’t need to modify Ray at all. It was just a few hundred lines of code to implement the sorting algorithm on top of Ray.”
Related Items:
Anyscale Branches Beyond ML Training with Ray 2.0 and AI Runtime
Anyscale Nabs $100M, Unleashes Parallel, Serverless Computing in the Cloud
From Amazon to Uber, Companies Are Adopting Ray
Leading Solution Providers

















