


February 15, 2023
Open Table Formats Square Off in Lakehouse Data Smackdown

(Lemberg-Vector-studio/Shutterstock)
If you’re constructing a data lakehouse today, you’ll need a table format to build on. But which open table format should you choose: Apache Iceberg, Databricks Delta Table, or Apache Hudi? A good place to start is industry analyst Tony Baer’s in-depth analysis, which slices and dices the open table formats and discusses their market uptake.
Open table formats have emerged as an indispensable component of the modern data lakehouse, which melds characteristics of data lakes and data warehouses into a single entity in support of customers’ advanced analytics and data science workloads.
Table formats are instrumental for getting the scalability benefits of the data lake and the underlying object store, while at the same time getting the data quality and governance associated with data warehouses. Previously, users had to pick one or the other, or replicate data from a lake to the warehouse and hope (or pray) that it stays up-to-date. But by using a table format, lakehouse users don’t have to accept tradeoffs and get the benefits of both.
Three table formats have emerged over the past few years to power data lakehouses. Apache Iceberg was created by engineers at Netflix and Apple who were tired of trying to use Apache Hive’s metastore to track data updates and manage transactions. Databricks created its own table format to live at the heart of its Delta Lake offering, and then open sourced it. Apache Hudi, meanwhile, was created by engineers at Uber to provide support for transactions for a massive data lake running on Hadoop.
“The whole elevator pitch for lakehouse is ACID transactions,” Baer said. “Not to turn it into an OLTP database, but is the data that we’re doing these analytics on or building these machine learning models on–is this valid data? Is it consistent? Or are we basically chasing our tail? That was the real driver of this. From that, you then get all the other goodies, like now with a table structure, we can do much more granular governance. Arguably there are ways to basically accelerate processing Parquet. But basically with tables, you can get much better performance that you can through file scans than you can with something like Impala.”
Baer has tracked the big data market for years through his reporting for publications like Venture Beat and The New Stack, as well as through his consulting firm, dbInsight. Lakehouses are at the cutting edge of the evolution of big data architectures, but when he realized nobody had done a deep dive into the technologies at the core of this new approach, he decided to do it himself.
He published the results today in a new report titled “Data Lakehouse open source market landscape.” Available to the public via download, the report (there are actually two reports: a 13-page primer and a 30-page technical deep dive) provides very useful information about Iceberg, Delta Table, and Hudi.
From a technical perspective, the three formats share many qualities and each meets the needs for a data lakehouse, Baer writes. All three “support ACID transactions, time travel, granular access control, multifunction (SQL and programmatic) analytics, and delivering superior performance compared to data lakes,” he writes. “There is roughly 80% to 90% functional parity between the lakehouse table formats.”
So which format is winning? Which format should you favor your new data lakehouse project? According to Baer, it depends. These are very early days still for data lakehouses and the table formats that power them, but they have different strengths.
“If you’re looking for full-featured, more real-time I’d go Hudi,” Baer told Datanami. “If I’m basically very Spark-oriented and very much in the in the Databricks ecosystem, that choice is obvious. If I’m looking for something that right now has a strongest credentials for being multivendor, I’d go Iceberg.”
While the technical capabilities of Iceberg, Delta Table, and Hudi are all fairly equal, what will elevate one over the others is adoption and market traction by users and the lakehouse vendor community.
All of the data lakehouse vendors have picked one or more table formats on which to build. Some are supporting all three formats with read and write capabilities; read support is easier to implement, he says, but write support is necessary to get the full ACID transaction capabilities of the table formats. (ACID transactions is the primary reason these formats exists in the first place, so that’s kind of a big deal.)
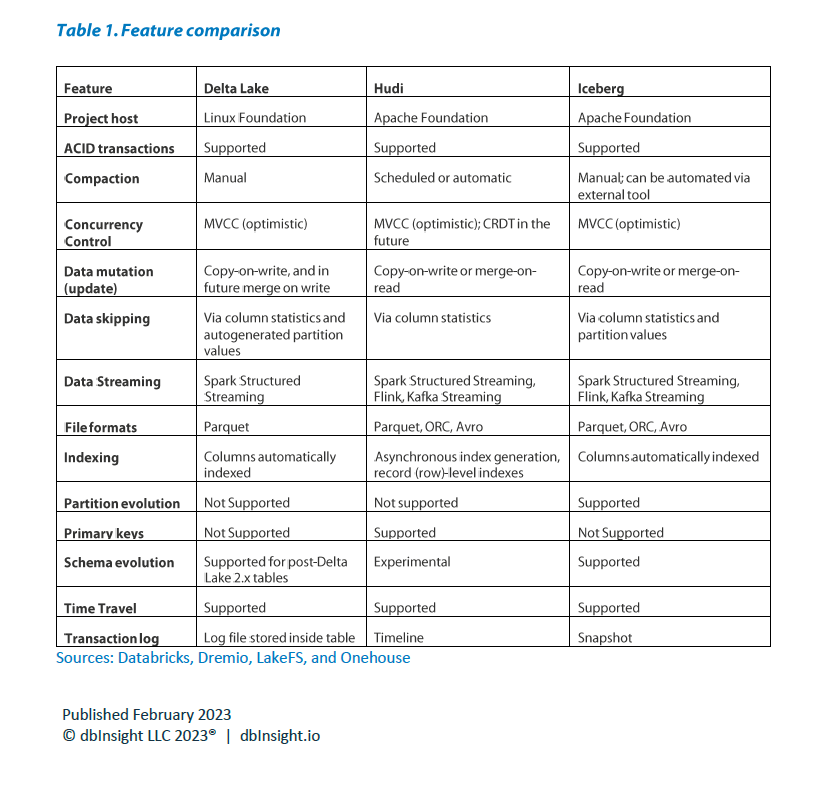
Open table format features (Source: dbInsight)
AWS, for instance, provides read and write support for all three formats with Amazon EMR and Amazon Glue, according to Baer’s research. However, Amazon Athena (its serverless Trino service) only provides read support for Delta Lake and Hudi, whereas it provides full read and write support with Iceberg.
Databricks also provides read and write support for all three formats, which is interesting, considering that it has a horse in the race with Delta Table. Kafka-backer Confluent put its eggs in the Hudi basket (with read/write support), as did Alibaba Cloud.
Microsoft Azure, which has a close partnership with Databricks, offers read/write support for Delta Lake with Azure Synapse, but it provides read/write support for Delta Lake and Hudi with Microsoft HDInsight, its Hadoop-based offering. Microsoft Azure Synapse Analytics, its newest analytics offering, provides read/write access to Delta Lake, but can only read data from Hudi and Iceberg.
Snowflake, on the other hand, has gone all-in with read/write support for Iceberg, which it announced one year ago. “Snowflake basically laid down the gauntlet,” Baer said. Snowflake said “we’re not just treating Iceberg as an external table, but we’re actually going to make these native tables. It’s like whoa–they’re actually putting some real skin in the game.”
Google Cloud seems, surprisingly, a bit behind in the game. It supports all three with Big Query, but it doesn’t provide write support at this point in time, according to Baer’s report. “Rome was not built in day. It makes sense for a vendor to start with read-only access,” he said. “Right now, it’s read-only. I expect within the year will be read plus write.”
The commercial Presto/Trino world also favors Iceberg slightly, although the open source projects tend to support all three with at least read support. Starburst, which backs the Trino fork of Presto, provides read/write support for Iceberg and Delta Lake, but only read access for Hudi. Ahana, a Presto startup, provides read/write support for Iceberg and read access for Hudi and Delta Lake. Dremio, which develops a storage-less SQL query engine similar to Trino/Presto, also provides read-write access for Iceberg but just reads the other ones.
Former Hadoop vendor Cloudera also supports Iceberg with read/write access; it does not provide even read access for the others. Tabular, the company founded by Iceberg co-creator Ryan Blue, supports only Iceberg (full read/write), while Onehouse, the company founded by Hudi’s creator, Vinoth Chandar, supports only Hudi (also with full read/write).![]()
What may tip the scales in favor of one open table format or another may be what the enterprise data warehouse vendors do. Baer said that, so far, Oracle, Teradata, IBM, and SAP are sitting on the sidelines. “They’re very tight-lipped about it I think because they’re still trying to figure this out,” he said. “I think they’re looking for the horse race to get to a fairly conclusive point.”
Oracle and Teradata currently have their own proprietary table formats, but Baer expects that they will adopt whatever their customers demand. He expects the market for data lakehouses and open table formats to sort itself out the next 12 to 18 months. During that span, one or two of them will emerge as the clear favorites.
Currently, Iceberg sits in the driver’s seat in terms of garnering that market momentum, Baer said, while Delta Table is sitting just behind. In many ways, the market has bifurcated into a Databricks vs. Snowflake war, and it’s clear which open table format those two vendors favor. Hudi has some technical advantages at this point in terms of classic “trickle feeding” of a warehouse, Baer says. But it’s clear there is some ground to make up there for the Hudi team.
While it has Microsoft Azure on its side, Databricks has hurdles in its path. While the company committed the entire Delta Lake project to the Linux Foundation back in 2019 and then committed the bulk of the Delta Tables code that had been proprietary to open source in June 2022, it still has some work to do. What’s preventing Delta Table from making a bigger splash in the ecosystem now is Databricks’ failure to put the project into neutral hands, Baer saids.
“I think it would be very smart for them to get somebody non-Databricks to run this, because at this point, like 95% of the content of Delta Lake is Databricks,” he said. “The reason why they did is they want to put the basics together to satisfy their requirement. That stuff now in place. Now we’re basically dealing with more like the icing on the cake, which is why they open sourced it. So I think the next step really would be…to find somebody that’s outside Databricks to chair of the project.”
You can read Baer’s entire report at the dbInsight website at www.dbinsight.io.
Related Items:
Onehouse Emerges from Stealth to Deliver Data Lakes in ‘Months, Not Years’
Why the Open Sourcing of Databricks Delta Lake Table Format Is a Big Deal
Snowflake, AWS Warm Up to Apache Iceberg
Applications:
Data Management
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Ahan, AWS, Cloudera, Databricks, dbInsight, Dremio, Google Cloud, IBM, Microsoft Azure, Onehouse, Oracle, SAP, Snowflake, Tabular, Teradata
Leading Solution Providers

















