


August 31, 2023
AI Ethics Issues Will Not Go Away

(3rdtimeluckystudio/Shutterstock)
Executives are right to be concerned about the accuracy of the AI models they put into production and tamping down on hallucinating ML models. But they should be spending as much time, if not more, addressing questions over the ethics of AI, particularly around data privacy, consent, transparency, and risk.
The sudden popularity of large language models (LLMs) has added rocket fuel to artificial intelligence, which was already moving forward at an accelerated pace. But even before the ChatGPT revolution, companies were struggling to come to grips with the need to build and deploy AI applications in an ethical manner.
While awareness is building over the need for AI ethics, there’s still an enormous amount of work to do by AI practitioners and companies that want to adopt AI. Looming regulation in Europe, via the EU AI Act, only adds to the pressure for executives to get ethics right.
The level of awareness over AI ethics issues is not where it needs to be. For example, a recent survey by Conversica, which builds custom conversational AI solutions, found that 20% of business leaders at companies who use AI “have limited or no knowledge” about their company’s policies for AI in terms of security, transparency, accuracy, and ethics, the company says. “Even more alarming is that 36% claim to be only ‘somewhat familiar’ with these issues,” it says.

Comedian, actor, and author Sarah Silverman is suing OpenAI (Featureflash Photo Agency/Shutterstock)
There was some good news last week from Thomson Reuters and its “Future of Professionals” report. It found, not surprisingly, that many professionals (45%) are eager to leverage AI to increase productivity, boost internal efficiencies, and improve client services. But it also found that 30% of survey respondents said their biggest concerns with AI were around data security (15%) and ethics (15%). Some folks are paying attention to the ethics question, which is good.
But questions around consent show no signs of being resolved any time soon. LLMs, like all machine learning models, are trained on data. The question is: who’s data?
The Internet has traditionally been a pretty open place, with a laissez faire approach to content ownership. However, with the advent of LLMs that are trained on huge swaths of data scraped off the Internet, questions about ownership have become more acute.
The comedian Sarah Silverman has generated her share of eyerolls during her standup routines, but OpenAI wasn’t laughing after Silverman sued it for copyright infringement last month. The lawsuit hinges on ChatGPT’s capability to recite large swaths of Silverman’s 2010 book “The Bedwetter,” which Silverman alleges could only be possible if OpenAI trained its AI on the contents of the book. She did not give consent for her copyrighted work to be used that way.
Google and OpenAI have also been sued by Clarkson, a “public interest” law office with offices in California, Michigan, and New York. The firm filed a class-action lawsuit in June against Google after the Web giant made a privacy policy change that, according to an article in Gizmodo, explicitly gives itself “the right to scrape just about everything you post online to build its AI tools.” The same month, it filed a similar suit against OpenAI.
The lawsuits are part of what the law practice calls “Together on AI.” “To build the most transformative technology the world has ever known, an almost inconceivable amount of data was captured,” states Ryan J. Clarkson, the firm’s managing partner, in a June 26 blog post. “The vast majority of this information was scraped without permission from the personal data of essentially everyone who has ever used the internet, including children of all ages.”

Google Cloud says it doesn’t use its business customers’ data to train its AI models, but its parent company does use consumer data to train its models (Michael Vi/Shutterstock)
Clarkson wants the AI giants to pause AI research until rules can be hammered out, which doesn’t appear forthcoming. If anything, the pace of R&D on AI is accelerating, as Google’s cloud division this week rolled out a host of enhancements to its AI offerings. As it helps enable companies to build AI, Google Cloud is also eager to help its business customers address ethics challenges, said June Yang, Google Cloud’s vice president of Cloud AI and industry solutions.
“When meeting with customers about generative AI, we’re increagingly asked question about data governance and privacy, security and compliance, reliability and sustainability, safety and responsibility,” Yang said in a press conference last week. “These pillars are really our cornerstone of our approach to enterprise readiness.
“When it comes to data governance and privacy, we start with the premise that your data is your data,” she continued. “Your data includes input prompt, model output, and training data, and more. We do not use customers’ data to train our own models. And so our customers can use our services with confidence knowing their data and their IP [intellectual property] are protected.”
Consumers have traditionally been the loudest when it comes to complaining about abuse of their data. But business customers are also starting to sound the alarm over the data consent issue, since it was discovered that Zoom had been collecting audio, video, and call transcript data from its video-hosting customers, and using it to train its AI models.
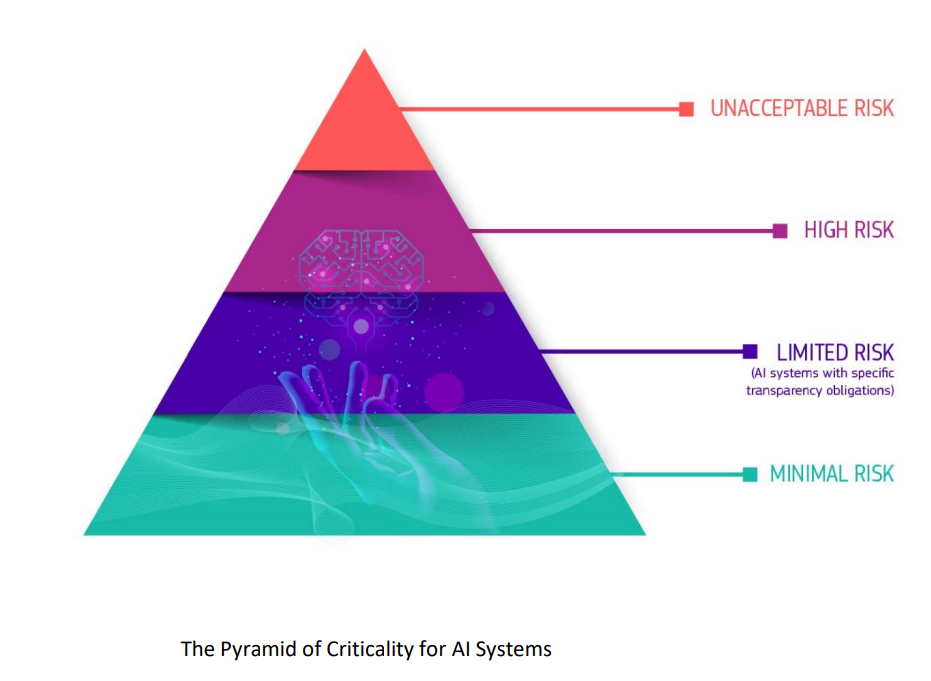
The proposed EU AI Act would categorize AI applications by risk
Without regulations, larger companies will be free to continue to collect vast amounts of data and monetize it however they like, says Shiva Nathan, the CEO and founder of Onymos, a provider of a privacy-enhanced Web application framework.
“The larger SaaS providers will have the power dynamic to say, you know what, if you want use my service because I’m the number one provider in this particular space, I will use your data and your customer’s data as well,” Nathan told Datanami in a recent interview. “So you either take it or leave it.”
Data regulations, such as the EU’s General Data Protection Regulation (GDPR) and the California Consumer Protection Act (CCPA), have helped to level the playing field when it comes to consumer data. Just about every website now asks for consent from users to collect data, and gives users the option to reject sharing their data. Now with the EU AI Act, Europe is moving forward with regulation on the use of AI.
The EU AI Act, which is still being hammered out and could possibly become law in 2024, would implement several changes, including restricting how companies can use AI in their products; require AI to be implemented in a safe, legal, ethical, and transparent manner; force companies to get prior approval for certain AI use cases; and require companies to monitor their AI products.
While the EU AI Act has some drawbacks in terms of addressing cybercrime and LLMs, it’s overall an important step forward, says Paul Hopton, the CTO of Scoutbee, a German developer of an AI-based knowledge platform. Moreover, we shouldn’t fear regulation, he said.

(Olivier Le Moal/Shutterstock)
“AI regulation will keep coming,” Hopton told Datanami. “Anxieties around addressing misinformation and mal-information related to AI aren’t going away any time soon. We expect regulations to rise regarding data transparency and consumers’ ‘right to information’ on an organization’s tech records.”
Businesses should take a proactive role in building trust and transparency in their AI models, Hopton says. In particular, emerging ISO standards, such as ISO 23053 and ISO 42001 or ones similar to ISO 27001, will help guide businesses in terms of building AI, assessing the risks, and talking to users about how the AI models are developed.
“Use these standards as a starting place and set your own company policies that build off those standards on how you want to use AI, how you will build it, how you will be transparent on your processes, and your approach to quality control,” Hopton said. “Make these policies public. Regulations tend to focus on reducing carelessness. If you identify and set clear guidelines and safeguards and give the market confidence in your approach to AI now, you don’t need to be afraid of regulation and will be in a much better place from a compliance standpoint when legislation becomes more stringent.”
Companies that take positive steps to address questions of AI ethics will not only gain more trust from customers, but it could help forestall government regulation that is potentially more stringent, he says.
“As scrutiny over AI grows, voluntary certifications of organizations following clear and accepted AI practices and risk management will provide more confidence in AI systems than rigid legislation,” Hopton said. “The technology is still evolving.”
Related Items:
Zoom Data Debacle Shines Light on SaaS Data Snooping
Europe Moves Forward with AI Regulation
Leading Solution Providers

















