


June 3, 2024
Snowflake Embraces Open Data with Polaris Catalog

(monticello/Shutterstock)
On the first day of its Data Cloud Summit today, Snowflake unveiled Polaris, a new data catalog for data stored in the Apache Iceberg format. In addition to contributing Polaris to the open source community, the catalog also enables Snowflake customers to use open compute engines with their Iceberg-based Snowflake data, including Apache Spark, Apache Flink, Presto, Trino, and Dremio.
The launch of Polaris represents a significant embrace of open source and open data on the part of Snowflake, which grew its business predominantly through a closed data stack, including proprietary table format and a proprietary SQL processing engine. The freeze on openness began to thaw in 2022, when Snowflake announced a preview of support for Iceberg, and the ice dam is melting rapidly with today’s launch of Polaris and the expected GA of Iceberg soon.
“What we’re doing here is introducing a new open data catalog,” Christian Kleinerman, EVP of product for Snowflake, said in a press conference last week. “It’s focused on being able to index and organize data that’s conformant with the Apache Iceberg open table format. And a very significant announcement for us is the fact that we are emphasizing interoperability with other query engines.”
Snowflake will offer a hosted version of Polaris that its customers can use with their Iceberg tables, which provide a metadata layer for Parquet files stored in cloud object stores, including Amazon S3 and equivalent offerings from Microsoft Azure and Google Cloud. But it also will be contributing Polaris source code to an open-source foundation within 90 days, enabling customers to run their own Polaris catalog or tap a third party to manage it for them.
“It is open source, even though we will provide a Snowflake-hosted version of this catalog,” Kleinerman said. “We will also enable customers and partners to host this catalog wherever they want to make sure that this new layer in the data stack does not become an area where any one vendor can potentially lock in customers data.”
With Polaris pointing the way to Iceberg tables, customers will be able to run analytics with their choice of engines, provided it supports Iceberg’s REST-based API. This eliminates lock-in at the data format and data catalog levels, Snowflake says in this blog post on Polaris.

Source: Snowflake
“Polaris Catalog implements Iceberg’s open REST API to maximize the number of engines you can integrate,” Snowflake writes in its blog. “Today, this includes Apache Doris, Apache Flink, Apache Spark, PyIceberg, StarRocks, Trino and more commercial options in the future, like Dremio. You can also use Snowflake to both read from and write to Iceberg tables with Polaris Catalog because of Snowflake’s expanded support for catalog integrations with Iceberg’s REST API (in public preview soon).”
Polaris will work with Snowflake’s broader data governance capabilities that are available via Snowflake Horizon, the company writes in its blog. This includes features like column masking policies, row access policies, object tagging and sharing, they write.
“So whether an Iceberg table is created in Polaris Catalog by Snowflake or another engine, like Flink or Spark, you can extend Snowflake Horizon’s features to these tables as if they were native Snowflake objects,” they write.
Vendors active in the open data community applauded Snowflake on the move, including Tomer Shiran, the founder of Dremio, which develops an open lakehouse platform based on Iceberg.
“Customers want thriving open ecosystems and to own their storage, data and metadata. They don’t want to be locked-in,” Shiran said in a press release. “We’re committed to supporting open standards, such as Apache Iceberg and the open catalogs Project Nessie and Polaris Catalog. These open technologies will provide the ecosystem interoperability and choice that customers deserve.”
Confluent, the company behind Apache Kafka and which has become a big supporter of Apache Flink, sees better interoperability ahead for customers accessing Snowflake data with TableFlow, Confluent’s new system for merging batch and streaming analytics.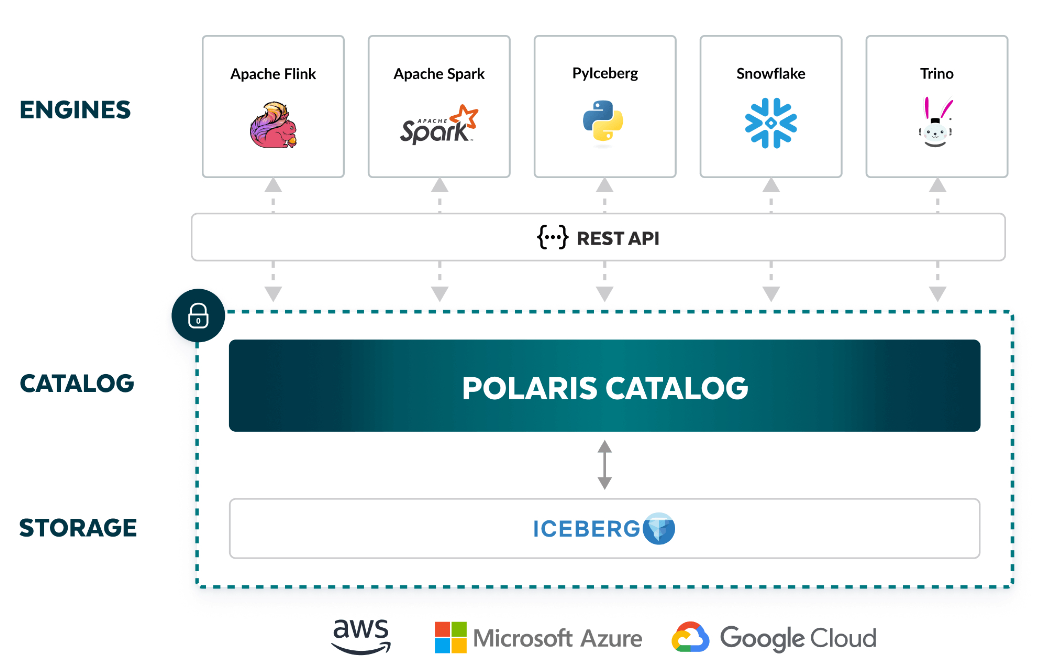
“At Confluent, we’re on a mission to break down data silos to help organizations power their businesses with more real-time insights,” Confluent Chief Product Officer Shaun Clowes said in Snowflake’s press release “With Tableflow on Confluent Cloud, organizations will be able to turn data streams from across the business into Apache Iceberg tables with one click. Together, Snowflake’s Polaris Catalog and Tableflow enable data teams to easily access these tables for critical application development and downstream analytics.”
Snowflake took its lumps from more open competitors in the past for its dedication to its proprietary data formats and processing engines. Those options are still available–and deliver higher performance than open options in some cases. But the move to launch Polaris and enable customers to use their choice of open query engines is a big move for Snowflake.
“This is not a Snowflake feature to work better with the Snowflake query engine,” Kleinerman said. “Of course, you will integrate and interoperate very well, but we are bringing together a number of industry partners to make sure that we can give our mutual customers at the end of the day choice to mix and match multiple query engines to be able to coordinate read and write activity and most important, to do so in an open fashion without having lock-in.”
Snowflake Data Cloud Summit 2024 takes place this week in San Franciso.
Related Items:
How Open Will Snowflake Go at Data Cloud Summit?
Snowflake, AWS Warm Up to Apache Iceberg
Applications:
Data Management
Technologies:
Cloud
Leading Solution Providers

















