


June 20, 2024
From Monolith to Microservices: The Future of Apache Spark

The days of monolithic Apache Spark applications that are difficult to upgrade are numbered, as the popular data processing framework is undergoing an important architectural shift that will utilize microservices to decouple Spark applications from the Spark cluster they’re running on.
The shift to a microservices architecture is being done through a project called Spark Connect, which introduced a new protocol, based on gRPC and Apache Arrow, that allows remote connectivity to Spark clusters using the DataFrame API. Databricks first introduced Spark Connect in 2022 (see the blog post “Introducing Spark Connect – The Power of Apache Spark, Everywhere”), and it became generally available with the launch of Spark 3.4 in April 2023.
Reynold Xin, a Databricks co-founder and its chief architect, spoke about the Spark Connect project and the impact it will have on Spark developers during his keynote address at last week’s Data + AI Summit in San Francisco.
“So the way Spark is designed is that all the Spark applications you write–your ETL pipelines, your data science analysis tools, your notebook logic that’s running–runs in a single monolithic process called a driver that include all the core server sides of Spark as well,” Xin said. “So all the applications actually don’t run on whatever clients or servers they independently run on. They’re running on the same monolithic server cluster.”
This monolithic architecture creates dependencies between the Spark code that people develop using whatever language (Scala, Java, Python, etc.) and the Spark cluster itself. Those dependencies, in turn, impose restrictions on what Spark users can do with their applications, specifically around debugging and Spark application and server upgrades, he said.
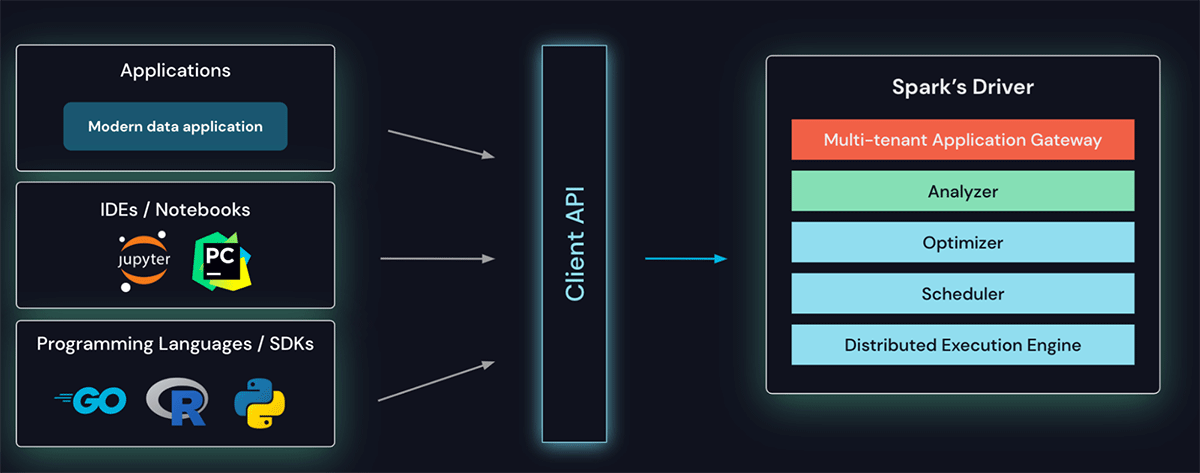
Spark Connect provides a new way for Spark clients to connect to Spark servers (Image courtesy Databricks)
“Debugging is difficult because in order to attach a debugger, you have to attach the very process that runs all of those things,” Xin said. “And…if you want to upgrade Spark, you have to upgrade the server, and you have to upgrade every single application running on the server in one shot. It’s all or nothing. And this is a very difficult thing to do when they’re all tightly coupled.”
The solution to that is Spark Connect, which takes Sparks’ DataFrame and SQL APIs and creates a language-agnostic binding for it, based on gRPC and Apache Arrow, Xin said. Spark Connect was originally pitched as making it easier to get Spark running away from the massive cluster running in the data center, such as application servers running on the edge or in mobile runtimes for data science notebooks. But the changes are such that the benefits will be felt far wider than “a mobile Spark.”
“This sounds like a very small change because it’s just introducing a new language binding and a new API that’s language-agnostic,” Xin said. “But it really is the largest architectural change to Spark since the introduction of DataFrame APIs themselves. And with this language-agnostic API, now everything else run as clients connecting to the language-agnostic API. So we’re breaking down that monolith into, you could think of it as microservices running everywhere.”
Having Spark applications decoupled from the Spark monolith will make upgrades much easier, Xin said.
“This makes upgrades super easy because the language bindings are designed to be language -agnostic, and forward- and backward-compatible, from an API perspective,” he said. “So you could actually upgrade the Spark server side, say from Spark 3.5 to Spark 4.0, without upgrading any of the individual applications themselves. And then you can upgrade applications one by one as your like at your own pace.”

Databricks co-founder and CTO Matei Zaharia, seen here at Data + AI Summit 2023, says he wished he had thought of Spark Connect at the beginning of the project
Similarly, debugging Spark applications gets easier, because the developer can attach the debugger to the individual Spark application running in its own isolated environment, thereby minimizing impact to the rest of the Spark apps running on the cluster.
There’s another benefit to having a language-agnostic API, Xin said–it makes bringing new languages to Spark much easier than it was before.
“Just in the last few months alone, we’ve seen sort of community projects that build Go bindings, Rust bindings, C# bindings, all this, and it can be built entirely outside the project with their own release cadence,” Xin said.
Databricks co-founder and CTO Matei Zaharia commented on the advent of a decoupled Spark architecture via Spark Connect during an interview with The Register last week. “We’re working on that now,” he said. “It’s kind of cool, but I wish we’d done it at the beginning, if we had thought about it.”
In addition to new Spark Connect features coming with Spark 4.0, Spark Connect is being introduced for the first time to Delta Lake with the 4.0 release of that open source project, where it is called Delta Connect.
Related Items:
Python Now a First-Class Language on Spark, Databricks Says
All Eyes on Databricks as Data + AI Summit Kicks Off
It’s Not ‘Mobile Spark,’ But It’s Close
Leading Solution Providers

















