


June 24, 2024
When Should You Choose a Dedicated Vector Database?
(DongIpix/Shutterstock
If you’re using a large language model (LLM) to develop a generative AI application, chances are pretty good that a vector database is somewhere in the mix. When it comes time to choose a vector database, there are plenty of options, and the biggest choice may be whether to go with a dedicated vector database or use an existing relational or NoSQL data store that has added vector storage and serving capabilities.
Vector databases have emerged as critical components for building GenAI applications, such as chatbots, AI agents, and question-answering systems. They’re important because they allow organizations to store vector embeddings created from their own private data, which they can then serve as part of the prompt sent to the LLM as part of the retrieval-augmented generation (RAG) pipeline.
Vector databases currently are the most popular type of database, according to DB-Engines.com, which uses a variety of inputs to determine its ranking, including mentions on the Web, Google searches, frequency of discussions on technical forums, and job offers, among others. While vector engines can also be used to power vector similarity searches (basically AI-powered search instead of keyword-powered search), the rise of LLMs and GenAI is driving the lion’s share of the popularity of vector databases.
You have plenty of options when it comes to choosing a vector database for your GenAI use case. There are free and open source options for the do-it-yourselfer, as well as enterprise vector databases that come with all the bells and whistles. You can run vector databases in the cloud or on-prem. But the biggest decision to make is the type of vector database you want: a dedicated vector database, or an existing database with added vector capabilities.
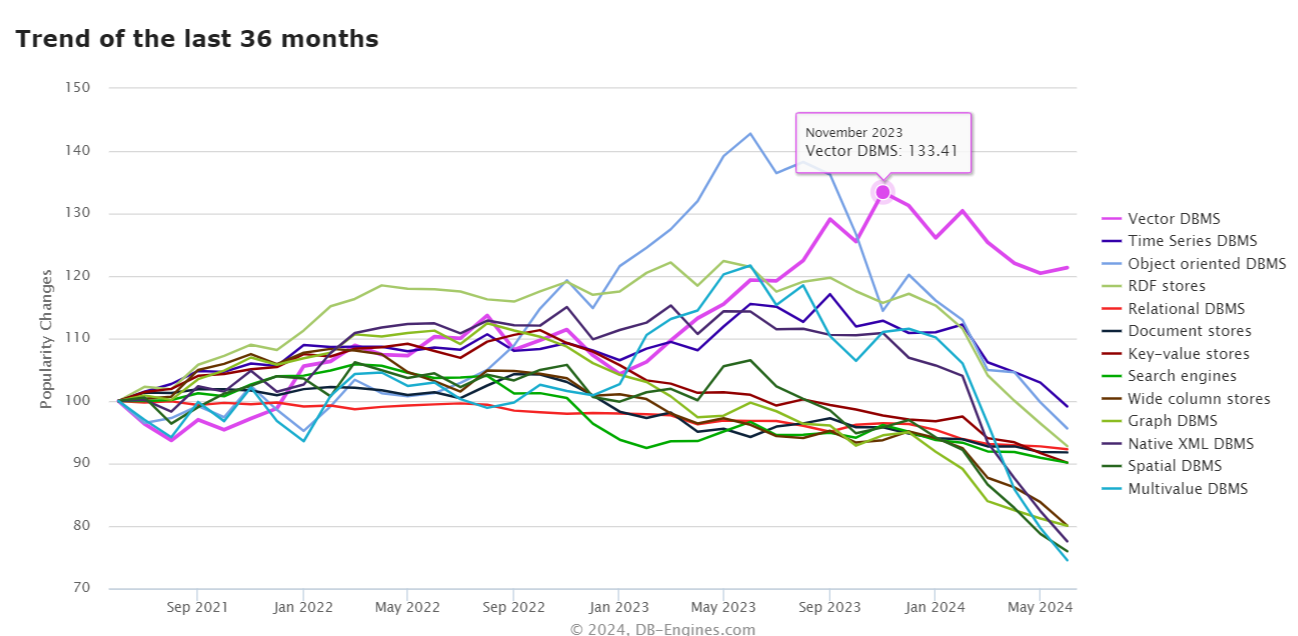
Vector databases are the most popular database type over the past three years, according to DB-Engines.com
Advantages of Dedicated Vector DBs
DB-Engine tracks eight pure-play vector databases, including Qdrant, a Berlin, Germany-based company that was founded by a pair of software engineers, André Zayarni and Andrey Vasnetsov. They had built a Python-based vector similarity search engine for a job search website in 2021 when they realized there was demand in the open source community for such a product.
Since OpenAI dropped ChatGPT on the world, 70% of Qdrant (pronounced “quadrant”) customers have been using it for GenAI use cases, Zayarni, who is the CEO, told Datanami recently. The GenAI revolution has powered a surge of interest in Qdrant, which has been downloaded 7 million times and put into production about 10,000 times, Zayarni said.
A dedicated vector database will deliver more consistent performance than a general-purpose database that has added vector capabilities for the same reason that organizations typically separate their transactional and analytical workloads: to prevent one type of workload from impacting another.

André Zayarni is the co-founder and CEO of Qdrant
“It’s about separating workloads from particular use cases,” he said. “If you have your user data, for example, and the vector data in the same database, then on the user data, you probably have a few queries, but on a vector database, it’s under a huge load.”
The approximate nearest neighbor algorithm that vector databases use to match user input with pre-build vector embeddings is “really hungry for RAM,” Zayarni said. “It’s like a noisy neighbor,” he said. “Whereas your core data will just require a bit of RAM, vector database will need gigabytes or more.”
Organizations that are just getting started with GenAI may find a general-purpose database works for storing and serving vector embeddings, Zayarni said. But as their GenAI application grows into the millions of embeddings, they will find the general-purpose database can’t scale to meet their needs, he said.
“You can do everything with Postgres, because Postgres has everything,” Zayarni said. “But let’s say we’re talking about just keyword search. You can do keyword search with Postgres as well. But if keyword search is important for your application, you’ll probably go for Elastic or something more dedicated, where you have a dedicated feature set, where you can optimize, and it’s not affecting your work database.”
Qdrant is a distributed database that can scale horizontally atop Kubernetes, with the biggest deployments exceeding 100 nodes. Qdrant also has built-in indexing and compression capabilities that are designed to keep data size more manageable.![]()
Qdrant offers an enterprise cloud solution that’s proving popular for organizations that developed their own vector capabilities in house, but now need something with more features and power, Zayarni said. “Those customers are migrating from some in-house build solutions they built years ago before a vector database existed,” he said.
There are tradeoffs with vector databases, however. To increase scalability, most vector databases will offer eventual consistency versus the ACID capability offered by relational databases, he said.
“Under the hood, it’s all about performance and scalability,” Zayarni said. “A distributed deployment is one of the keys where traditional database are more focused on transactional data and data consistency.”
Vector + DB
Despite the technical advantages that dedicated vector databases hold over their general-purpose counterparts, there’s no denying the popularity of using general-purpose databases to store and serve vector embeddings, either for GenAI or AI-powered search use cases.
While DB-Engines tracks eight pure-play vector databases, there are a total of 16 databases in its vector database comparison. That’s because eight multi-modal engines, such as Kdb, Aerospike, and CrateDB also make the list. And if you click the box to include secondary models, suddenly there are 27 databases in the DB-Engines vector database list, with the top dominated by databases with names like Oracle, Postgres, MongoDB, Redis, and Elasticsearch.
Andi Gutmans, the general manager and vice president of databases at Google Cloud, recently conducted an informal survey on LinkedIn, in which he asked his followers whether they’re using a dedicated vector database or a general-purpose database with vector capabilities. Out of about 200 responses, 51% were using existing databases, while only about 30% were using purpose-built vector databases.
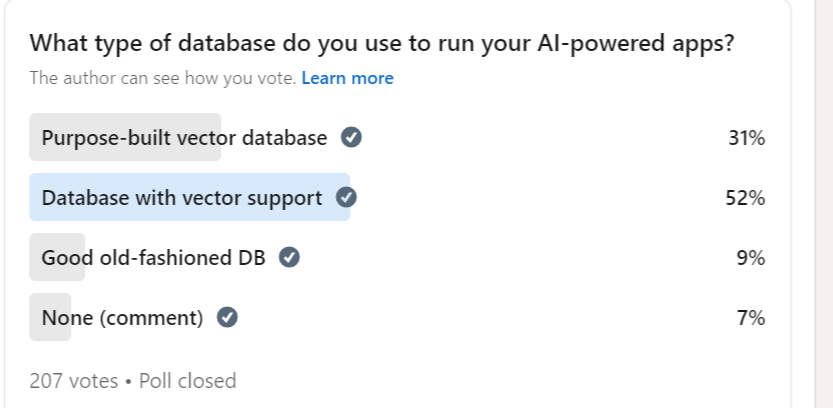
General-purpose databases are most popular for vector workloads, according to Gutmans poll
While the survey wasn’t scientific, it helped to confirm Gutmans’ instinct, which is that general-purpose databases will ultimately be the preferred vehicle for vector storage and search capabilities in the future
“If you think about the first phase was, folks were using purpose-bult vector databases because that’s where the vectors are sitting,” he told Datanami in an interview. “But now I think companies are realizing, I’ve got all this data locked up in my databases, whether it’s Postgres or Oracle or MySQL or Redis, and it is just so much easier to bring that processing into the database that already exists.”
Google’s strategy is to bring vectors into every one of its data stores, including its hosted offerings for Postgres, MySQL, Redis, and Cloud Spanner, among others.
“We’ve innovated on Redis, on MySQL. We have very differentiated vector capabilities on Postgres, better than what open source has,” Gutmans said. “We’ve actually been innovating on vectors for over 12 years for the Google business, so we’re externalizing some of those proprietary algorithms into some of our offerings.”

Andi Gutmans, the general manager and vice president of databases
Nobody really runs at Google scale except for, well, Google and a group of companies you can count on one hand. For organizations that are content to leverage Google-developed technology that may never be open sourced, they can get a competitive advantage–particularly as the company’s new Spanner Data Boost functionality is rolled out, which links the globally distributed transactional database with BigQuery, its analytical database.
Google also does workload separation in ways that the rest of the world can only dream about, which gives it another advantage as it tries to finally merge the analytical and transactional world. Spanner Data Boost will be the first time that hybrid transactional analytical processing (HTAP) is “done right,” Gutmans said.
For the rest of us, choosing between a dedicated vector database comes down to making time-honored IT choices: What capabilities does your actual workload require today, what capabilities do you think it will require tomorrow, and how much extra are you willing to spend today to avoid the pain of moving tomorrow?
Gutmans conceded that purpose-build vector stores have a place in the world today, even if that place may be shrinking in the years to come.
“Our belief is that, as we go down this route, we will see a significant increase in usage of these high-end vector capabilities within existing data stores vs purpose built. But I’m not going to say there’s not going to be a market for it. I think there is,” he said.
“There’s some good purpose-built vector database out there,” he continued. “I’m not saying there’s no space for them. We also have one, Vertex AI Vector Search. So I think you definitely have use case where that’s good, but I will probably disagree with the long term assertion of that.”
Related Items:
Forrester Slices and Dices the Vector Database Market
Vector Databases Emerge to Fill Critical Role in AI
Applications:
Data Management
Technologies:
Middleware
Leading Solution Providers

















